Self-Correcting Responses improve answer quality by having an independent verifier LLM review agent outputs. The verifier grades responses for accuracy, completeness, and policy adherence, and can trigger automatic reprompting when quality falls below acceptable thresholds.
What It Does
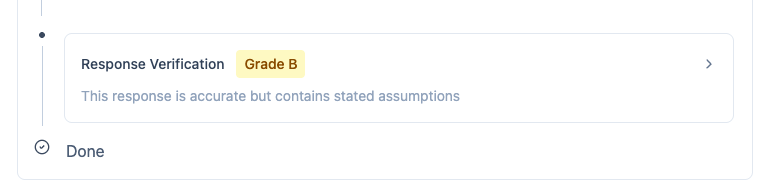
Section titled “What It Does”After an agent generates a response, a separate verifier model evaluates the answer before it reaches the user. The verifier assigns a grade (A/B/C/F), provides reasoning for the grade, and can automatically request a better response if quality is insufficient.
Why It Matters
Section titled “Why It Matters”AI agents make mistakes. Sometimes they:
- Misunderstand the question
- Provide incorrect information
- Miss important context
- Violate company policies
- Give incomplete answers
Self-correcting responses catch these mistakes before users see them, improving reliability and building trust in your AI systems.
How It Works
Section titled “How It Works”
The Verification Loop
Section titled “The Verification Loop”Primary Agent Responds
The configured agent processes the user's question and generates an initial response using its tools and knowledge.
Verifier Evaluates
An independent LLM (typically a different model) reviews the response against criteria like accuracy, completeness, policy compliance, and helpfulness.
Grade Assignment
The verifier assigns a letter grade:
- A - Excellent response, no issues
- B - Good response, minor issues
- C - Acceptable but has problems
- F - Failed, significant issues
Auto-Reprompt Decision
If enabled and grade falls below threshold (typically C or F), the system automatically asks the agent to try again with the verifier's feedback.
Final Response
User receives the improved response (or original if quality was sufficient).
Verification Criteria
Section titled “Verification Criteria”The verifier evaluates responses on multiple dimensions:
- Accuracy - Is the information correct?
- Completeness - Does it fully answer the question?
- Policy Compliance - Does it follow company guidelines?
- Tool Usage - Did it use tools appropriately?
- Tone - Is the communication style appropriate?
- Safety - Does it avoid harmful content?
Configuration
Section titled “Configuration”Enable for Specific Roles
Section titled “Enable for Specific Roles”Start conservatively and expand:
const chatAppConfig: ChatAppConfig = { featureOverrides: { verifyResponse: { enabled: true, // Only for internal power users initially allowedRoles: ['pika:content-admin'], autoRepromptThreshold: 'C' } }};Configure Grading Thresholds
Section titled “Configure Grading Thresholds”Adjust based on your quality requirements:
verifyResponse: { enabled: true, autoReprompt: true, autoRepromptThreshold: 'C', // Reprompt for C or F maxRepromptAttempts: 2, // Try twice max showGradeToUser: false // Hide from external users}Control Visibility
Section titled “Control Visibility”Different visibility for different audiences:
// Internal users see everythingverifyResponse: { enabled: true, allowedUserTypes: ['internal-user'], showGradeToUser: true, showReasoningToUser: true}
// External users get benefits without seeing mechanicsverifyResponse: { enabled: true, allowedUserTypes: ['external-user'], showGradeToUser: false, showReasoningToUser: false}Use Cases
Section titled “Use Cases”Customer-Facing Chatbots
Section titled “Customer-Facing Chatbots”Ensure high quality before customers see responses:
- Catch factual errors in product information
- Verify policy compliance in support responses
- Ensure professional tone in customer communications
- Prevent inappropriate or off-brand messaging
High-Stakes Domains
Section titled “High-Stakes Domains”Extra verification for sensitive areas:
- Financial Advice - Verify calculations and recommendations
- Medical Information - Check accuracy of health guidance
- Legal Guidance - Ensure policy compliance
- Customer Commitments - Verify promises and commitments
Training and Development
Section titled “Training and Development”Use verification during agent development:
- Identify common failure patterns
- Refine agent instructions based on verifier feedback
- Test improvements against previous failure cases
- Build confidence before production deployment
Key Benefits
Section titled “Key Benefits”Catch Mistakes Early
Section titled “Catch Mistakes Early”Problems identified before users see them:
- Incorrect information corrected automatically
- Missing context added on second attempt
- Policy violations prevented
- Tone issues addressed
Transparent Quality
Section titled “Transparent Quality”Grade visibility for debugging and improvement:
- Internal teams see verification reasoning
- Track quality trends over time
- Identify agents needing refinement
- Measure improvement from changes
Configurable Quality Bars
Section titled “Configurable Quality Bars”Different standards for different situations:
- Strict (A/B only) for customer-facing apps
- Moderate (B/C acceptable) for internal tools
- Aggressive (auto-reprompt on C) for high stakes
- Conservative (no reprompt) for testing
Continuous Improvement
Section titled “Continuous Improvement”Verifier feedback drives agent refinement:
- Identifies instruction gaps
- Reveals tool usage issues
- Highlights knowledge gaps
- Guides training data needs
Performance Considerations
Section titled “Performance Considerations”Latency Impact
Section titled “Latency Impact”Verification adds processing time:
- Typical overhead: 1-3 seconds per response
- Auto-reprompt: Additional 3-5 seconds when triggered
- User experience: Most users don't notice with streaming
Mitigation strategies:
- Start verification while user reads streamed response
- Show "verifying..." indicator during verification
- Only verify for high-stakes responses
- Disable for simple queries
Cost Impact
Section titled “Cost Impact”Additional LLM calls increase costs:
- Verification call: Smaller context than primary agent
- Reprompt calls: Full agent invocation with feedback
- Typical increase: 20-30% of base agent cost
Optimization strategies:
- Use smaller/cheaper model for verification
- Enable only for important chat apps
- Skip verification for simple queries
- Set max reprompt attempts
Advanced Features
Section titled “Advanced Features”Custom Verification Prompts
Section titled “Custom Verification Prompts”Tailor verification criteria:
verifyResponse: { enabled: true, customVerificationPrompt: ` Evaluate this customer support response for: 1. Accuracy of product information 2. Compliance with refund policy (max $500 without approval) 3. Professional, empathetic tone 4. Complete answer to customer question
Assign grade and explain reasoning. `}Verification Bypass Rules
Section titled “Verification Bypass Rules”Skip verification when not needed:
verifyResponse: { enabled: true, skipForSimpleQueries: true, // Skip "hello", "thanks" skipForLowConfidence: true, // Skip when agent uncertain skipAfterGoodStreak: 10 // Skip after 10 A grades}Learning from Verification
Section titled “Learning from Verification”Track patterns to improve agents:
- Log all verifier feedback
- Analyze common failure modes
- Update instructions based on patterns
- Test fixes against historical failures
Best Practices
Section titled “Best Practices”Start with Internal Users
Section titled “Start with Internal Users”Roll out gradually:
- Phase 1: Enable for internal power users only
- Phase 2: Measure impact, tune thresholds
- Phase 3: Extend to all internal users
- Phase 4: Enable for external users (hidden grades)
Set Appropriate Thresholds
Section titled “Set Appropriate Thresholds”Match thresholds to use case:
- Customer-facing: Reprompt on C or F
- Internal tools: Accept C grades
- High-stakes: Accept only A/B grades
- Development: Log all but don't reprompt
Monitor Verification Metrics
Section titled “Monitor Verification Metrics”Track important indicators:
- Grade distribution (% A/B/C/F)
- Reprompt frequency
- Reprompt success rate (improvement after reprompt)
- User satisfaction correlation with grades
Use Feedback for Training
Section titled “Use Feedback for Training”Continuously improve agents:
- Review F-graded responses weekly
- Update instructions to address common issues
- Add tools to fill capability gaps
- Refine prompts based on verifier feedback
Debugging
Section titled “Debugging”Review Verification Details
Section titled “Review Verification Details”Access full verification context:
- Original agent response
- Verifier's grade and reasoning
- Reprompt attempts and results
- Final delivered response
Analyze Grade Trends
Section titled “Analyze Grade Trends”Identify patterns:
- Which agents get low grades?
- What types of questions cause failures?
- Does time of day affect quality?
- Are certain tools problematic?
Test Verification Logic
Section titled “Test Verification Logic”Validate verification behavior:
- Send test queries with known-good answers
- Send queries that should fail verification
- Measure verification accuracy
- Tune verification prompts as needed
Getting Started
Section titled “Getting Started”Enable Self-Correction
Step-by-step guide to configuring verification.
View in Weather Sample
See self-correction working in the sample app.
Understand the Concepts
Deep dive into verification architecture.
Related Capabilities
Section titled “Related Capabilities”Answer Reasoning
See detailed traces of what agents do and why.
LLM-Generated Feedback
Automatic analysis of completed sessions for improvement.
Insights
Session metrics and quality tracking automatically generated.