LLM-Generated Feedback provides automatic, objective analysis of completed chat sessions. After each session ends, a separate AI reviews the entire conversation and generates actionable feedback about what worked well and what could be improved.
What It Does
Section titled “What It Does”When a user completes a chat session, an independent LLM analyzes the full conversation asynchronously and generates structured feedback:
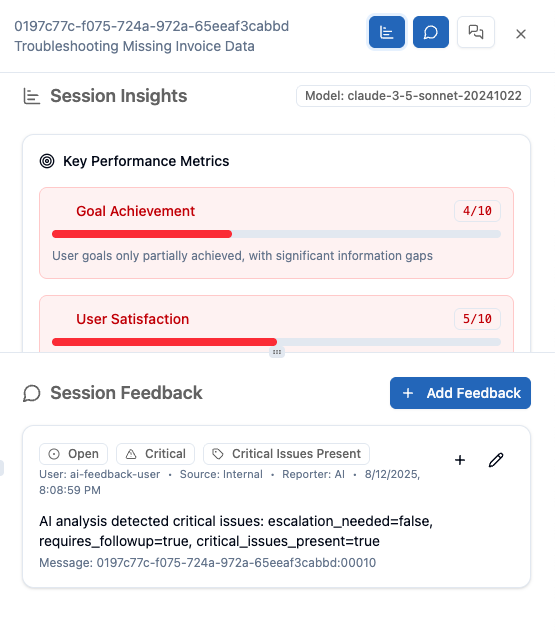
- Session summary - Goal, outcome, and overall quality
- Strengths identified - What the agent did well
- Issues observed - Problems with responses or tool usage
- Improvement suggestions - Specific recommendations for prompts, tools, or knowledge
This happens in the background without affecting user experience, providing continuous quality monitoring across all your chat applications.
Why It Matters
Section titled “Why It Matters”Manual review of chat sessions doesn't scale. As usage grows:
- You can't read every conversation
- Patterns are hard to spot across thousands of sessions
- Issues might go unnoticed until users complain
- Improvement priorities are unclear
LLM-Generated Feedback solves this by providing automatic, consistent analysis of every session, helping you:
- Identify patterns - See recurring issues across many sessions
- Prioritize improvements - Focus on problems affecting most users
- Measure progress - Track if changes improve feedback scores
- Catch edge cases - Find unusual scenarios needing attention
How It Works
Section titled “How It Works”
Asynchronous Analysis
Section titled “Asynchronous Analysis”User completes session
Chat session ends (user closes chat or period of inactivity)
EventBridge triggers analysis
Background Lambda function queued to analyze the session
Feedback LLM reviews conversation
Independent AI reads full conversation with context:
- User messages and agent responses
- Tool invocations and results
- Traces and reasoning steps
- Verification grades (if enabled)
Structured feedback generated
LLM produces JSON feedback with:
- Overall assessment
- Specific strengths and issues
- Actionable recommendations
- Confidence scores
Feedback stored and indexed
Results written to DynamoDB and OpenSearch for exploration
Non-Blocking Operation
Section titled “Non-Blocking Operation”Critical for user experience:
- Runs completely asynchronously
- Never slows down user chats
- Processes during low-traffic periods
- Gracefully handles failures without user impact
Generated Feedback Structure
Section titled “Generated Feedback Structure”Session Summary
Section titled “Session Summary”High-level assessment:
{ "sessionGoal": "User wanted to check order status and update delivery address", "goalAchieved": true, "overallQuality": "good", "summary": "Session successfully helped user track order and update address. Agent used tools appropriately and provided clear information."}Strengths Identified
Section titled “Strengths Identified”What worked well:
{ "strengths": [ "Agent quickly identified need for order-lookup tool", "Clear explanation of order status and tracking", "Proactively offered address update option", "Professional, empathetic tone throughout" ]}Issues Observed
Section titled “Issues Observed”Problems that need attention:
{ "issues": [ { "severity": "medium", "description": "Agent didn't verify user identity before updating address", "turnNumber": 3, "recommendation": "Add authentication check to address-update tool" }, { "severity": "low", "description": "Response to final question was overly verbose", "turnNumber": 5, "recommendation": "Refine instructions to be more concise" } ]}Improvement Suggestions
Section titled “Improvement Suggestions”Actionable recommendations:
{ "suggestions": [ { "category": "tool", "priority": "high", "suggestion": "Create dedicated authentication tool to verify user identity before sensitive operations" }, { "category": "instructions", "priority": "medium", "suggestion": "Add guideline to instructions: 'Be concise in confirmations and status updates'" }, { "category": "knowledge", "priority": "low", "suggestion": "Add FAQ about typical delivery timeframes to reduce tool calls" } ]}Configuration
Section titled “Configuration”Enable Feedback Generation
Section titled “Enable Feedback Generation”const chatAppConfig: ChatAppConfig = { featureOverrides: { llmFeedback: { enabled: true, feedbackModel: 'anthropic.claude-3-5-sonnet-20241022-v2:0', analysisDepth: 'detailed', // 'basic' or 'detailed' minSessionTurns: 2 // Only analyze sessions with 2+ turns } }};Customize Feedback Prompts
Section titled “Customize Feedback Prompts”Tailor analysis to your needs:
llmFeedback: { enabled: true, customPrompt: ` Analyze this customer support session focusing on: 1. Policy compliance (refund policy, privacy policy) 2. Customer satisfaction indicators 3. Efficiency (resolved in minimum turns) 4. Tool usage appropriateness
Provide specific, actionable feedback. `}Schedule Analysis
Section titled “Schedule Analysis”Control when analysis runs:
llmFeedback: { enabled: true, analysisDelay: 300, // Wait 5 minutes after session end batchSize: 10, // Process 10 sessions per batch scheduleExpression: 'rate(15 minutes)' // Run every 15 min}Use Cases
Section titled “Use Cases”Quality Monitoring
Section titled “Quality Monitoring”Track agent performance over time:
- Monitor feedback trends across sessions
- Identify degrading quality
- Measure impact of instruction changes
- Compare performance across chat apps
Agent Development
Section titled “Agent Development”Improve agents based on real usage:
- Identify instruction gaps
- Discover missing tools
- Find knowledge base gaps
- Refine prompts iteratively
Prioritization
Section titled “Prioritization”Focus improvements on high-impact issues:
- See which issues occur most frequently
- Identify problems affecting satisfaction
- Find quick wins vs major overhauls
- Build data-driven roadmap
Compliance Monitoring
Section titled “Compliance Monitoring”Ensure policy adherence:
- Track policy violations automatically
- Identify problematic patterns
- Verify training effectiveness
- Generate compliance reports
Exploring Feedback
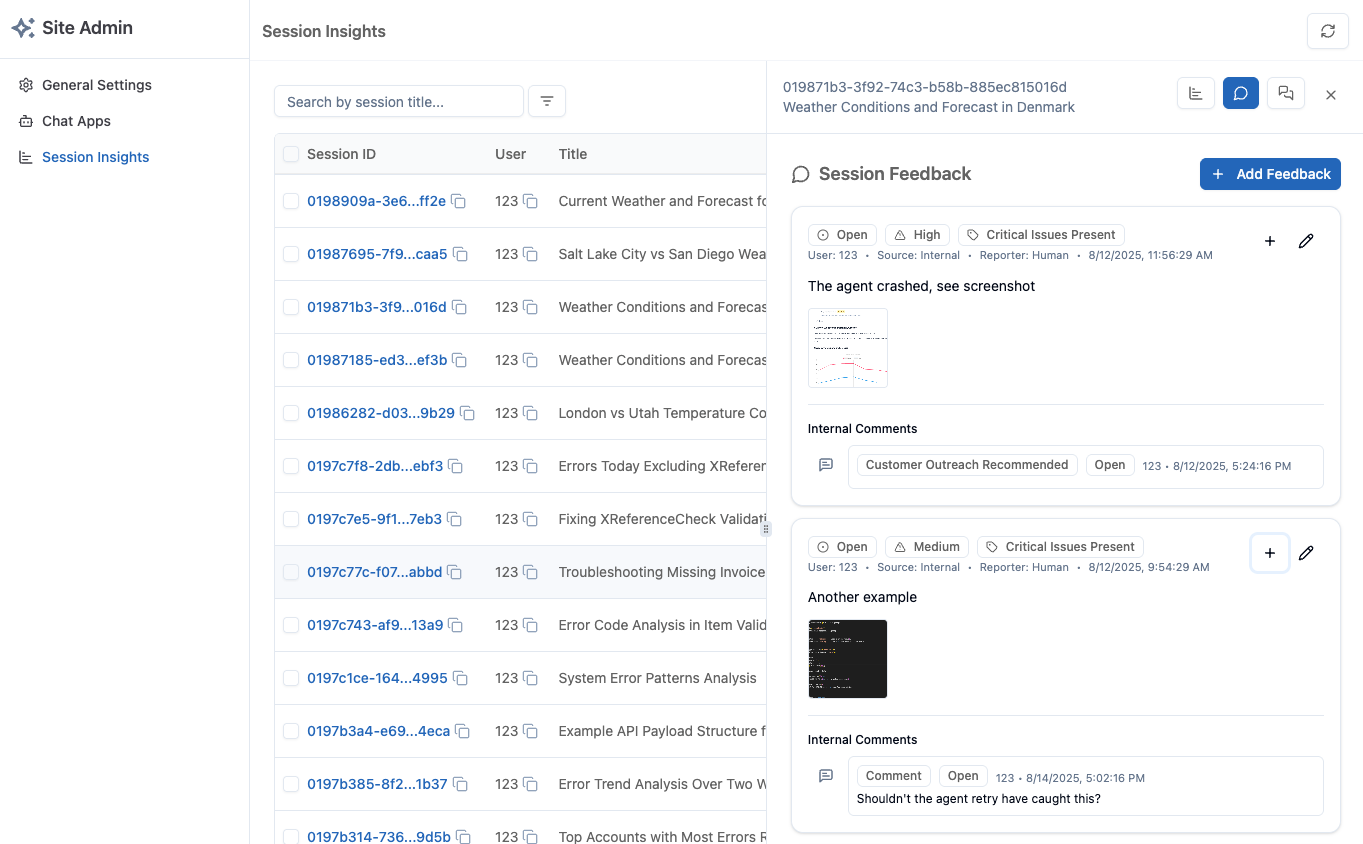
Section titled “Exploring Feedback”Admin Site Integration
Section titled “Admin Site Integration”Browse and filter feedback:
- View feedback for any session
- Filter by quality score
- Search for specific issues
- Compare across date ranges
Aggregate Analysis
Section titled “Aggregate Analysis”See patterns across sessions:
- Most common issues
- Frequently suggested improvements
- Quality trends over time
- Per-agent performance comparison
Export and Reporting
Section titled “Export and Reporting”Use feedback data externally:
- Export to CSV/JSON for analysis
- Feed into BI dashboards
- Generate executive reports
- Share with stakeholders
Best Practices
Section titled “Best Practices”Start Simple
Section titled “Start Simple”Begin with basic feedback:
- Phase 1: Enable for one chat app
- Phase 2: Review generated feedback quality
- Phase 3: Refine feedback prompts as needed
- Phase 4: Expand to all chat apps
Act on Feedback
Section titled “Act on Feedback”Close the loop:
- Review feedback weekly
- Implement high-priority suggestions
- Measure impact of changes
- Document what worked
Combine with Human Feedback
Section titled “Combine with Human Feedback”LLM feedback + user feedback = complete picture:
- LLM identifies technical issues
- Users report satisfaction and outcomes
- Combined view shows full quality landscape
- Prioritize based on both signals
Set Up Alerts
Section titled “Set Up Alerts”Get notified of important issues:
- High severity issues detected
- Quality drops below threshold
- New failure patterns emerge
- Compliance violations found
Advanced Features
Section titled “Advanced Features”Feedback Confidence Scores
Section titled “Feedback Confidence Scores”Not all feedback is equally reliable:
{ "issue": "Agent provided incorrect pricing", "confidence": 0.85, // High confidence "reasoning": "Verified against product database"}Use confidence to prioritize review:
- High confidence (>0.8): Likely accurate
- Medium confidence (0.5-0.8): Worth reviewing
- Low confidence (<0.5): May be false positive
Historical Comparison
Section titled “Historical Comparison”Track improvement over time:
- Compare feedback pre/post changes
- Measure issue resolution rates
- Show quality trend lines
- Demonstrate ROI of improvements
Pattern Detection
Section titled “Pattern Detection”Identify systemic issues:
- Same issue across many sessions
- Failure patterns in specific scenarios
- Tool reliability problems
- Knowledge gaps
Custom Metrics
Section titled “Custom Metrics”Define your own quality indicators:
customMetrics: [ { name: 'policyCompliance', description: 'Adherence to company policies', weight: 0.3 }, { name: 'efficiency', description: 'Resolved in minimum turns', weight: 0.2 }, { name: 'satisfaction', description: 'Customer satisfaction signals', weight: 0.5 }]Performance and Cost
Section titled “Performance and Cost”Processing Time
Section titled “Processing Time”Feedback generation is fast:
- Average: 2-5 seconds per session
- Runs asynchronously (no user impact)
- Batch processing optimized
- Scales automatically
Cost Considerations
Section titled “Cost Considerations”Additional LLM calls:
- One feedback call per session
- Smaller context than primary agent
- Can use cheaper model
- Typical cost: $0.01-0.05 per session
Optimization strategies:
- Skip simple sessions (1-2 turns)
- Use smaller model for feedback
- Batch process during off-peak
- Sample subset of sessions if needed
Getting Started
Section titled “Getting Started”Enable Feedback Generation
Configure LLM feedback for your chat apps.
View in Admin Site
Explore generated feedback in the admin interface.
Understanding Feedback
Deep dive into feedback generation architecture.
Related Capabilities
Section titled “Related Capabilities”Insights
Automatic session metrics complement LLM feedback.
Self-Correcting Responses
Real-time quality control vs post-session analysis.
Admin Site
Browse and analyze all feedback in one place.