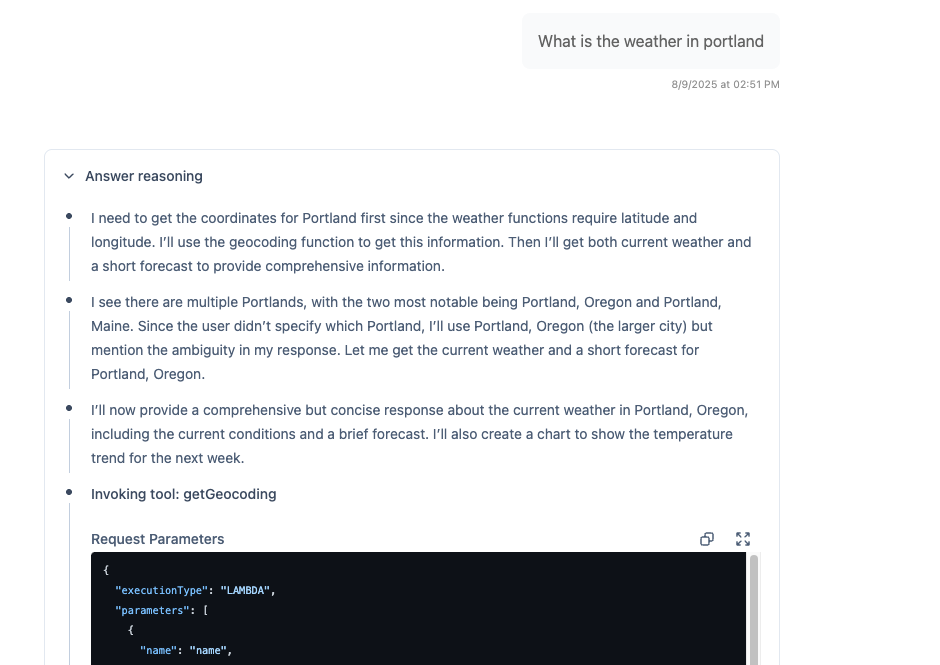
Answer Reasoning, also known as Traces, provides complete transparency into how AI agents think through problems. See the agent's step-by-step reasoning, tool invocations, and decision-making process in real-time as responses stream.
What It Does
Section titled “What It Does”When enabled, users can see detailed traces of the agent's thought process:
- Step-by-step reasoning as the agent works through problems
- Tool invocations with inputs and outputs
- Decision points and why the agent made specific choices
- Quality assessments and confidence levels
- Error explanations when things go wrong
The reasoning begins streaming back long before the answer itself arrives, helping the user feel results are coming quickly and providing insight into how the agent is approaching the problem. This is particularly helpful for long-running queries where the user may not be able to see the progress.
Why It Matters
Section titled “Why It Matters”AI agents can feel like black boxes - they give answers but you don't know how they arrived at them. This makes it difficult to:
- Trust the responses - Hard to verify correctness without seeing the work
- Debug issues - Can't identify where things went wrong
- Improve agents - Don't know what to fix without visibility
- Educate users - Can't explain how the AI works
Transparent reasoning solves all of these problems, building trust and enabling continuous improvement.
How It Works
Section titled “How It Works”
Streaming Reasoning
Section titled “Streaming Reasoning”As the agent processes a request, reasoning events stream to the UI:
User sends message
Question is sent to the agent
Reasoning starts streaming
Agent's thought process appears in real-time:
- "Analyzing the user's question..."
- "I need to look up order information..."
- "Calling order-lookup tool..."
Tool invocations shown
Tool calls with inputs and outputs displayed:
- Tool name and purpose
- Input parameters
- Execution time
- Returned results
Final answer synthesized
Agent explains how it used tool results to formulate the answer
Verification (if enabled)
Independent verifier's assessment with grade and reasoning
Two Levels of Detail
Section titled “Two Levels of Detail”Basic Traces - General thought process:
- High-level reasoning steps
- Tool names and purposes
- Success/failure indicators
- User-friendly explanations
Detailed Traces - Complete technical detail:
- Full tool schemas and parameters
- Execution timing and performance
- Model invocation details
- Internal state and context
- Error stack traces
Trace Visibility Control
Section titled “Trace Visibility Control”Role-Based Access
Section titled “Role-Based Access”Control who sees traces:
const chatAppConfig: ChatAppConfig = { featureOverrides: { traces: { enabled: true, allowedRoles: ['pika:content-admin', 'customer-support'] }, detailedTraces: { enabled: true, allowedRoles: ['pika:site-admin'] // Admins only } }};User Type Separation
Section titled “User Type Separation”Different visibility for different audiences:
// Internal users see full tracestraces: { enabled: true, allowedUserTypes: ['internal-user']}
// External users see no traces (default)traces: { enabled: false, allowedUserTypes: ['external-user']}Per-Session Toggle
Section titled “Per-Session Toggle”Users can toggle trace visibility:
- Show traces when debugging
- Hide traces for cleaner reading experience
- Persists preference per user
Use Cases
Section titled “Use Cases”Agent Development and Debugging
Section titled “Agent Development and Debugging”Essential during development:
- See exactly what the agent is thinking
- Identify where reasoning goes wrong
- Verify tool calls are working correctly
- Test edge cases and failure modes
- Measure response quality
Customer Support Training
Section titled “Customer Support Training”Help support teams understand agents:
- Learn how agents solve problems
- Understand tool capabilities
- Train on effective agent usage
- Identify when to escalate
Quality Assurance
Section titled “Quality Assurance”Monitor agent performance:
- Review traces for problematic sessions
- Identify patterns in failures
- Verify policy compliance
- Assess response quality
User Education
Section titled “User Education”Teach users how AI works:
- Demystify AI responses
- Build trust through transparency
- Show capabilities and limitations
- Explain tool usage
Trace Information
Section titled “Trace Information”Reasoning Steps
Section titled “Reasoning Steps”What the agent is thinking:
Thinking: The user is asking about order #12345.I should use the order-lookup tool to get the current status.Tool Invocations
Section titled “Tool Invocations”Complete tool execution details:
Tool: order-lookupInput: { orderId: "12345" }Status: SuccessDuration: 243msOutput: { orderId: "12345", status: "shipped", trackingNumber: "1Z999AA1...", estimatedDelivery: "2024-11-01"}Decision Points
Section titled “Decision Points”Why the agent chose a specific path:
Decision: Based on the order status being "shipped",I'll provide the tracking information and estimated delivery date.Verification Results
Section titled “Verification Results”Quality assessment with reasoning:
Verification: Grade AReasoning: Response accurately conveys the order status,provides tracking information, and sets appropriate delivery expectations.All information matches the tool output.Advanced Features
Section titled “Advanced Features”Search and Filter Traces
Section titled “Search and Filter Traces”Find specific information:
- Search within trace content
- Filter by tool name
- Find successful/failed invocations
- Locate specific reasoning patterns
Export Traces
Section titled “Export Traces”Extract for analysis:
- Download full trace logs
- Export as JSON for processing
- Include in support tickets
- Archive for auditing
Trace Annotations
Section titled “Trace Annotations”Add context to traces:
- Mark important decision points
- Flag issues for review
- Add explanatory notes
- Link to related documentation
Performance Considerations
Section titled “Performance Considerations”Minimal Overhead
Section titled “Minimal Overhead”Traces add negligible latency:
- Streaming happens in parallel
- No additional LLM calls required
- Storage is append-only (fast writes)
- UI updates are asynchronous
Storage Requirements
Section titled “Storage Requirements”Traces are stored with sessions:
- Average 1-5KB per session
- Compressed in DynamoDB
- Indexed in OpenSearch
- Subject to retention policies
Best Practices
Section titled “Best Practices”Start with Internal Users
Section titled “Start with Internal Users”Roll out visibility gradually:
- Phase 1: Enable for developers and admins
- Phase 2: Extend to power users and support staff
- Phase 3: Consider carefully before showing to external users
- Phase 4: Never show detailed traces to external users
Use for Debugging
Section titled “Use for Debugging”Essential debugging tool:
- Always enable traces during development
- Review traces when users report issues
- Compare traces for good vs bad responses
- Document trace patterns for training
Protect Sensitive Information
Section titled “Protect Sensitive Information”Be cautious with trace visibility:
- Traces may contain sensitive data
- Tool outputs might have PII
- Reasoning may reveal business logic
- Restrict access appropriately
Leverage for Training
Section titled “Leverage for Training”Use traces to educate:
- Train support staff on agent capabilities
- Document common reasoning patterns
- Create examples of good agent behavior
- Build internal knowledge base
Integration with Other Features
Section titled “Integration with Other Features”Self-Correcting Responses
Section titled “Self-Correcting Responses”Traces show the full correction loop:
- Initial agent reasoning and response
- Verifier's analysis and grade
- Reprompt with verifier feedback
- Improved reasoning and final answer
LLM-Generated Feedback
Section titled “LLM-Generated Feedback”Feedback references specific trace points:
- "In step 3, the agent should have considered..."
- "The tool invocation at timestamp X failed because..."
- "The reasoning in the final synthesis missed..."
Insights
Section titled “Insights”Traces feed into insights generation:
- Goal completion inferred from reasoning
- Confidence derived from explicit statements
- Issues identified from error traces
- Complexity measured by reasoning depth
Getting Started
Section titled “Getting Started”Enable Traces
Configure trace visibility for your chat apps.
View in Weather Sample
See traces working in the sample application.
Understand Trace Architecture
Deep dive into how traces work.
Related Capabilities
Section titled “Related Capabilities”Self-Correcting Responses
Verification results appear in traces with full reasoning.
LLM-Generated Feedback
Feedback references specific trace elements.
Admin Site
Review traces for all sessions in one place.